


- ReTV 8th Online General Assembly - December 9, 2020
- DataTV 2020 Webinar: Data-driven Personalisation of Television - September 29, 2020
- Under the radar: ReTV solutions featured in the EU innovation Radar - August 7, 2020
On September 14, ReTV and MeMAD held the online DataTV 2020 webinar. Bringing together experts in the field of (meta)data and television, from both academia and the industry, the webinar was a suitable occasion to share the latest state of the art and innovations in this field.
The webinar opened with keynote speaker Sara Kepplinger from SNIPIN . As an expert in User Experience design, Sara introduced a video application centred on personalized storytelling. The tool mixes available video snippets and users’ personal recordings, changing video objects and resulting in a personalized story. You can have a look at the full presentation here.
Lyndon Nixon, ReTV project coordinator, introduced our project’s solutions: the Topic Compass prediction feature that helps to identify future topics of interest to the audience, and the Content Wizard, which helps users to prepare and make a publication on the best available digital channel. You can have a look at the full presentation here and watch his presentation below.
Meanwhile, Lauri Saarikoski from fellow Horizon 2020 project MeMAD and co-organizer of the webinar, introduced MeMAD supported solutions. With a focus on the revolution of digital storytelling, Lauri presented the MeMAD prototype platform, used for metadata storage, GUIs, media manipulation tools and workflow coordination. Have a look at his presentation here and watch his presentation below.
Kalev Leetaru gave a very interesting talk about the U.S.-based GDELT Project, a massive open database of the world’s news media, and it’s new Global Entity Graph and dataset annotated by Google’s Cloud Natural Language API. The GDELT Project uses powerful machine learning tools to codify and organize global social-scale data, and is supported by Google Jigsaw and a collection of universities, academic publishers, internet companies, government funding, and the Internet archive. This solution allows users to research in ways that have never before been possible such as comparing coverage of events across regions, news organizations, and languages, or reverse-search images to verify news stories.
In his highly technical Overview of the immersive media approach in MPEGI, Imed Bouazizi from Qualcomm described the new format that is being developed to meet the need to encode richer data from immersive media, include more metadata in files, and compress video for machine understanding. The new MPEGI standard will be released after testing and validation around mid 2021.
The last presentation came from Mike Armstrong (BBC R&D) & Joe Kent (BBC Newslab). In their talk Steps towards automation in the production of interactive content, Mike and Joe Kent shared a work in progress in the development of tools for media producers. Kent explained the Slicer workflow that helps to describe production content at a detailed clip-level in the Programme Information System Ontology, helping producers access footage for re-use. Armstrong’s presentation Algorithmic production for Personalisation and Interactivity looked at a new tool called StoryFormer that helps producers create object-based media. Blending the Slicer API and the StoryFormer will create opportunities for new forms of storytelling, bringing together audience data and prediction with rich metadata.
DataTV Lightning talks
The webinar also included four sessions of lightning talks. Ahti Ahde’s talk TV Programmes Are Narrative Sequences incorporated cognitive science, complexity and post-structural philosophy to analyze processes of audience reception. Using notions from Gilles Deleuze, this project aims to shed light on the use of familiar tropes in storytelling used in broadcasting.
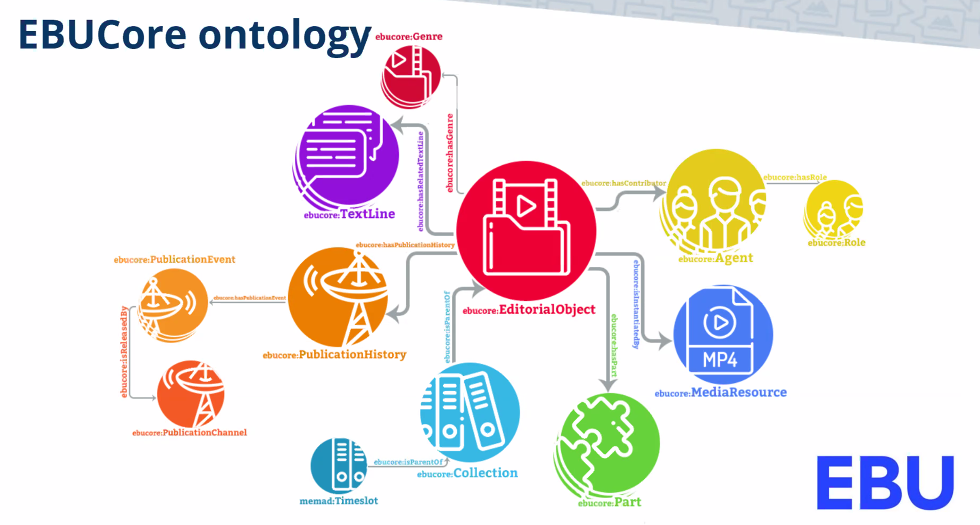
Ismail Harrando’s presentation described EUROCOM’s development of a knowledge graph for TV and Radio content developed by the MeMAD project Partnering with YLE and INA, this project brings legacy program metadata and automatic annotations using AI services into the EBUCore Ontology through controlled vocabulary converted in python. The AI services include speech-to-text, facial recognition, machine translation, deep captioning, and content segmentation. This will allow for easier integration and an interface for specific pre-created queries.
Another interesting participation was Pasquale Lisena’s talk FaceRec: an AI-based System for Face Recognition in Video Archives. FaceRec is a project of Eurocom that identifies celebrities on the web and trains machines to identify them in still and moving images. The steps of the process include 1. Crawl the web 2. Train a classifier, 3. Recognise the faces 4. Cluster recognitions. The tool is now available online, find it here. You can have a look at the full presentation here and watch his presentation below.
Oana Inel’s talk User Preferences for Personalized Explanations for Video Summaries described a study exploring how audiences respond to machine-created video summarization clips. Because audiences are not aware of how aspects of the video could be amplified, diminished or omitted, or how fragments are selected, the researchers explored ways to increase transparency through explanations. The explanations are categorized in Dimensions of Transparency; Semantic Coverage, Quantity Coverage, Semantic Prominence and Distance. User studies and explanations are available through the following links:
Find her presentation here and watch the session below
Next steps: a new DataTV community
The webinar wrapped up with a panel session, where presenters emphasize the need to continue discussions surrounding ongoing innovations and issues related to data and television. With this in mind, it was decided to create the new DataTV community, an online space that aims to foster the dialogue and exchange on core interests such as: the research on the type of available data and how we can use it to generate value in the TV domain, the ongoing standards and what’s happening in the industry.
Join the community and stay updated with the latest developments in the industry!
Comments are closed.