
The Trans-Vector Platform (TVP) is a flexible toolkit of individual software components that empowers broadcasters and media companies to continuously predict the topics of most interest to their audiences and optimise the success of their content published on multiple digital channels in terms of reach and engagement, allowing them to optimize decision-making processes in content marketing and publication scheduling. By using a modular architecture, the TVP can be easily extended, integrated into existing workflows and use synergies between systems where it makes sense.
Trans-Vector Platform
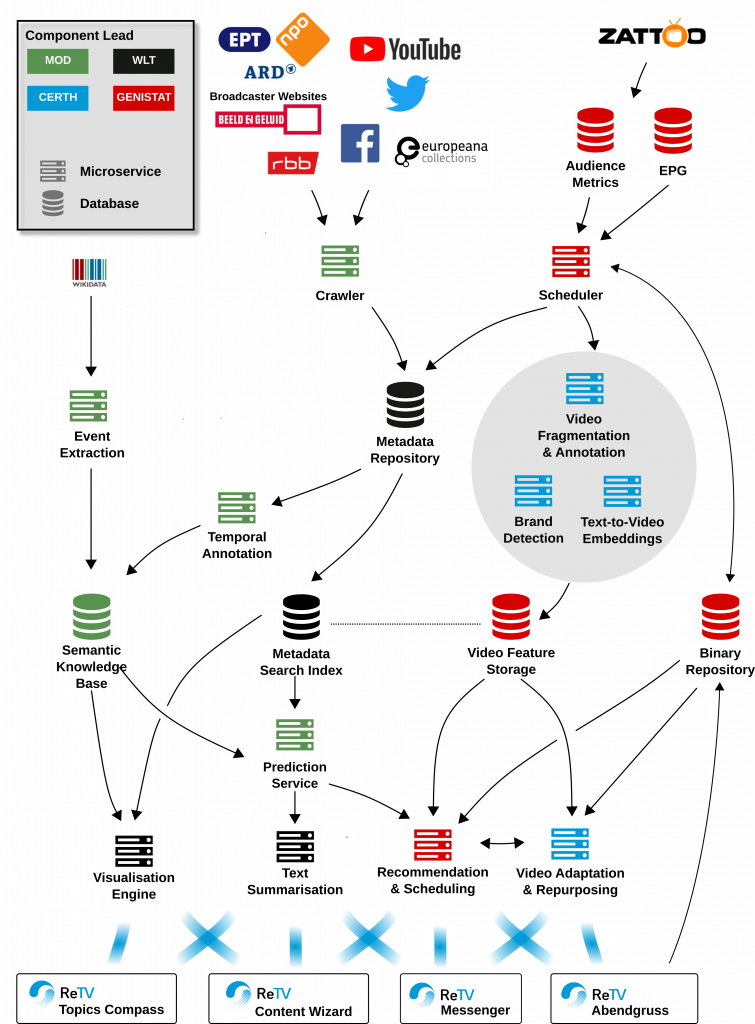
The TVP is composed of the following components:
- Crawler performs online data collection from multiple sources which are configurable (Websites and/or social networks) and encompasses NLP & NER functionalities to generate for each data item (Webpage or social network posting) a document with its annotations (raw text and mentioned entities), These documents can be stored for further analysis and processing.
- Temporal Annotation module provides the capability to extract date references from within documents as additional annotations.
- Semantic Knowledge Base (SKB) is used both as a source of lexemes and entities for document annotation and as an event database, where events are both automatically extracted from online sources (the Event Extraction module) and can be manually added by users via our SKBEditor Web interface.
- Prediction service uses the annotations of documents which reference future dates to predict the topics of interest to an audience in a future period of time. These functionalities are individually accessible via APIs so that organizations can (i) collect data from the online discourse on the Web and in social networks, (ii) query for events of interest within a specified time period, as well as (iii) access predictions for trending topics among their audience. All APIs can be configured specifically for each user, e.g. regarding data sources, event types or the audience characteristics for prediction.
- Metadata Repository provides the scalable and secure data storage and management for the documents collected and annotated by the Crawler.
- Metadata Search Index provides efficient large scale query and document retrieval for other services such as the Prediction API.
- Visualisation Engine provides VaaS (Visualisation as a Service) for data visualisations based on analytics over the document store (e.g. exploring topics of discussion in online sources, sentiment in social networks towards a TV programme etc.).
- Text summarization service – available either as an API or Web interface – automatically shortens longer texts for Web or social media publication focused on the keywords which are predicted to have the most attention.
- Video Fragmentation & Annotation, Brand Detection and Text-to-video Embeddings components that provide the following functionalities: (i) temporally fragmenting videos and annotating them with concept labels; (ii) detecting brands/logos/objects in video; (iii) searching within video collections/archives by using the automatically-generated concept/brand/logo/object annotations, or also by using natural language (free-text) queries even though there is no pre-existing textual metadata for the videos in your archive; and (iv) automatically creating short videos (summaries) from long-form content, and/or adapting their aspect ratio to the requirements of different distribution channels. These functionalities allow for finding the exact video content you are looking for, and transforming it for its intended re-use. The CERTH services for video asset management are available in the form of Software as a Service (SaaS) and, in cases where the volume of content to be processed or privacy/security concerns make it preferable, as Software that can be installed at the customer’s own computing infrastructure. They can be used by companies that build VOD platforms and MAMs (B2B) for introducing advanced AI-based functionalities in their integrated solutions and products, or by media organizations that wish to introduce such functionalities into their existing workflows and systems (B2C).
- Editor Interface for the 4u2 Smart Speaker Skill is a system that allows broadcasters to upload segments of TV shows and have them served in a personalized manner to their audience. This allows broadcasters to reuse content at very low cost and keeps their audience engaged. It can be integrated into existing smart speaker skills and video workflows through an API.
- Editor Interface for the 4u2 Messenger allows broadcasters and archives to send personalised content to their audience through chat platforms like Telegram and Facebook Messenger. Just like the smart-speaker system, they allow broadcasters to keep their viewers engaged beyond the television at very low cost. The chatbot learns for each user individually which content they find interesting by building anonymized profiles. The chatbot can be integrated into existing video management systems and it will then automatically distribute content.
To see how these services can be applied to different scenarios in media organisations, check out the four ReTV use cases:
- Topics Compass monitors and analyses web articles and social media posts in order to help media professionals make sense of trending stories and support them in preparing future publications.
- Content Wizard combines most of the TVP functionalities to provide a seamless, semi-automated workflow for the selection, creation and publication of optimised audiovisual content across social media channels.
- 4u2 builds on the TVP’s capabilities to understand audiovisual content and audience interests at any given time in order to automatically distribute personalised content.
- Content sWitch uses on-demand personalisation capabilities to enhances the linear TV experience by replacing ads with alternatives tailored for each viewer.
Would you like to discuss how the Trans-Vector Platform services could enhance the services of your organisation? Then don’t hesitate to contact us.